
Tagged: shell scripts
How to create a Twitter archive of your tweets – Use WkhtmlToPDF and TweetsToRSS to save your tweets as PDF
“com.vsubhash.bash.twitter-to-pdf.txt” is a Unix/Linux shell script for archiving all messages posted by a Twitter account in PDF format.
The command to use is:
bash com.vsubhash.bash.twitter-to-pdf.txt \ realDonaldTrump \ 4000 \ nojs
The first argument to bash is the shell script. The second argument is the Twitter account. The third argument is the number of tweets to archive. The fourth argument is used if the Javascript used by TweetsToRSS causes problems with WKhtmlToPDF.
This code assumes that WKhtmlToPDF is available in /opt. Else, you need to update the script. WKhtmlToPDF uses konqueror browser under the hood. The good thing about it is that all HTML links are preserved.
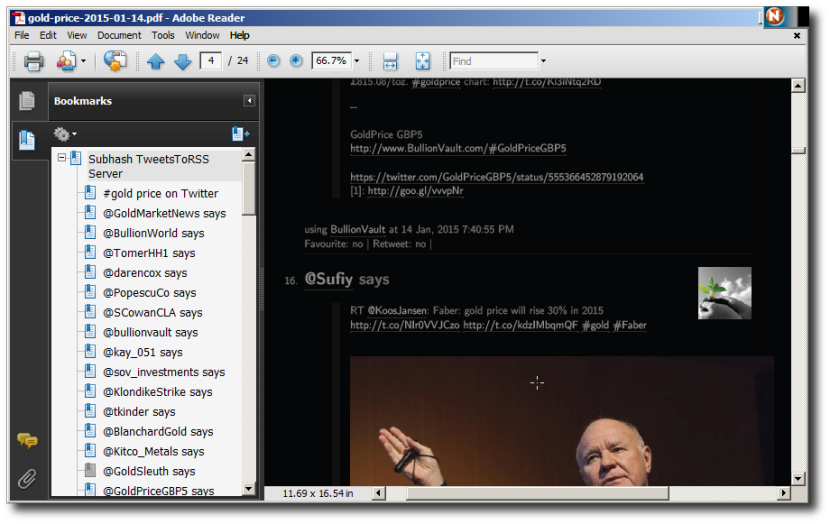
Tweets to PDF conversion
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| if [ $# -lt 2 ]; then | |
| echo -e "The format is:\n\t\e[35m`basename $0` \e[35;1mtwitter-handle-or-hashtag number-of-tweets [nojs]\e[0m" | |
| exit | |
| fi | |
| # A backup of all files will be available in this Logs directory | |
| if [ ! -d ~/Logs ]; then | |
| mkdir ~/Logs | |
| fi | |
| cd ~/Logs | |
| # Declare variables | |
| iTweetsPerPage=100 | |
| iPage=1 | |
| iMaxPages=1 | |
| iRemainder=0 | |
| sDocs="" | |
| # Initialize variables | |
| let "iMaxPages = $2 / $iTweetsPerPage" | |
| let "iRemainder = $2 % $iTweetsPerPage" | |
| if [ $iRemainder -gt 0 ]; then | |
| let "iMaxPages = iMaxPages + 1" | |
| fi | |
| # Javascript to remove YouTube IFrames. | |
| sJavaScript="(function(){var arIframes=document.getElementsByTagName('iframe');var n = arIframes.length; for (var i=0;i<n;i++){ arIframes[0].parentElement.removeChild(arIframes[0]);}})()" | |
| # If Javascript scripts cause problems, use the "nojs" argument to this | |
| # shell script | |
| if [ $# -eq 3 ]; then | |
| sJavaScriptFlag="–disable-javascript" | |
| else | |
| sJavaScriptFlag="–enable-javascript" | |
| fi | |
| # Create archives | |
| for (( iPage=1; iPage $1-meta.txt | |
| echo "InfoValue: Subhash TweetsToRSS (www.vsubhash.com)" >> $1-meta.txt | |
| echo "InfoKey: Title" >> $1-meta.txt | |
| echo "InfoValue: The complete Twitter archive of $1" >> $1-meta.txt | |
| echo "InfoKey: Subject" >> $1-meta.txt | |
| echo "InfoValue: Collection of all tweets from $1" >> $1-meta.txt | |
| echo "InfoKey: Author" >> $1-meta.txt | |
| echo "InfoValue: $1" >> $1-meta.txt | |
| echo "InfoKey: Keywords" >> $1-meta.txt | |
| echo "InfoValue: $1, twitter, tweets, archive" >> $1-meta.txt | |
| pdftk Complete-Twitter-Archive-of-$1.pdf \ | |
| update_info $1-meta.txt \ | |
| output The-Complete-Twitter-Archive-of-$1.pdf | |
| if [ $# -eq 0 ]; then | |
| notify-send "Twitter archive" "Completed for @$1" | |
| else | |
| notify-send "Twitter archive" "Error occurred for @$1" | |
| fi | |
| if [ -f The-Complete-Twitter-Archive-of-$1.pdf ]; then | |
| cp ./The-Complete-Twitter-Archive-of-$1.pdf ~/Desktop/The-Complete-Twitter-Archive-of-$1.pdf | |
| fi | |
| # Cleanup | |
| if [ ! -d $1-backup ]; then | |
| mkdir $1-backup | |
| fi | |
| if [ -d $1-backup ]; then | |
| mv -f $1-archive-*.pdf ./$1-backup | |
| mv -f Complete-Twitter-Archive-of-$1.pdf ./$1-backup | |
| mv -f $1-meta.txt ./$1-backup | |
| mv ./The-Complete-Twitter-Archive-of-$1.pdf ./$1-backup | |
| fi |
Create a Twitter Archive – A PDF dump of all tweets from an account
I have 51 tweets in my @SubhashBrowser account. So, this command will create the Twitter dump.
bash twitter-to-pdf.txt SubhashBrowser 51
Subhash TweetsToRSS must be running when you execute this command. You also need wkhtmltopdf and pdftk installed. The content of twitter-to-pdf.txt is as follows:
# Initialize variables
iPage=1
iMax=1
iRemainder=0
sDocs=""
let "iMax = $2 / 25"
let "iRemainder = $2 % 25"
if [ $iRemainder -gt 0 ]; then
let "iMax = iMax + 1"
fi
sJavaScript =
"(function(){ " +
" var arIframes=document.getElementsByTagName('iframe');" +
" var n = arIframes.length; " +
" for (var i=0;i<n;i++) { " +
" arIframes[0].parentElement.removeChild(arIframes[0]); " +
"}})()" # Javascript to remove YouTube iframes generated by TweetsToRSS
# Create archives
for (( iPage=1; iPage<=iMax; iPage++ ))
do
echo "Converting http://localhost:8080/?q=%40$1&output=html&older-than=$iPage"
wkhtmltopdf --quiet \
--encoding utf-8 \
--debug-javascript --javascript-delay 60 --run-script "$sJavaScript" \
--user-style-sheet wkhtml_twitter_style.css \
--image-dpi 300 -s A3 \
--margin-top 0 --margin-right 0 --margin-bottom 0 --margin-left 0 \
"http://localhost:8080/?q=%40$1&output=html&older-than=$iPage" \
"@$1-archive-$iPage.pdf"
sDocs="$sDocs @$1-archive-$iPage.pdf"
done
# Combine archives
pdftk $sDocs cat output Complete-Twitter-Archive-of-@$1.pdf
# Updated metadata
echo "InfoKey: Creator" > $1-meta.txt
echo "InfoValue: Subhash TweetsToRSS (www.vsubhash.com)" >> $1-meta.txt
echo "InfoKey: Title" >> $1-meta.txt
echo "InfoValue: The complete Twitter archive of @$1" >> $1-meta.txt
echo "InfoKey: Subject" >> $1-meta.txt
echo "InfoValue: Collection of all tweets from @$1" >> $1-meta.txt
echo "InfoKey: Author" >> $1-meta.txt
echo "InfoValue: V. Subhash" >> $1-meta.txt
echo "InfoKey: Keywords" >> $1-meta.txt
echo "InfoValue: $1, twitter, tweets, archive" >> $1-meta.txt
pdftk Complete-Twitter-Archive-of-@$1.pdf \
update_info $1-meta.txt \
output The-Complete-Twitter-Archive-of-@$1.pdf
# Cleanup
mkdir $1-backup
if [ -d $1-backup ]; then
mv @$1-archive-*.pdf ./$1-backup
mv Complete-Twitter-Archive-of-@$1.pdf ./$1-backup
mv $1-meta.txt ./$1-backup
fi

All 51 tweets from my @SubhashBrowser has been dumped into a PDF archive.
Twitter seems to have placed a limit of just above 3000 to the number of tweets you can pull from an account. Here is the complete Twitter archive of US President Donald J Trump (@realDonaldTrump).
BASH script to check for broken hyperlinks from a list

for sLine in $(< url-list.txt); do
echo "Checking $sLine"
sStatus=`curl -s -I $sLine | grep -i "HTTP/1.1 "`
echo -e "\t$sStatus"
sStatusCode=`echo $sStatus | awk '{ print $2}'`
if [ "$sStatusCode" -eq "200" ]; then
echo $sLine >> valid-urls-list.txt
echo -e "\tValid => \e[33;1m$sLine\e[0m"
else
echo $sStatus
echo -e "\tInvalid => \e[31;1m$sLine\e[0m"
fi
done
BASH script to check a list of proxy IP addresses
Some websites in North America do allow access to people from the rest of the world. You can access them via publicly available proxy IP addresses in that region. There are many websites that provide lists of proxy IP addresses (http://pastebin.com/search?q=proxies). Some proxies work on a special port. You just need to append the port number to the IP with a colon in between. For example, 46.165.250.235:3128. I usually copy the table to Calc (spreadsheet program) and then data-transform the pasted text to obtain the IP:port combination.
Testing the IPs in the list can be a hassle if you have do it manually using a browser. This BASH script can automate it. Just run it and see which proxy is fast. Press Ctrl+C when you find a good proxy. This script expects the proxy IP addresses to be placed in a file named proxy-list.
sed '/^$/d' proxy-list.txt > proxy-list2.txt for sLine in $(< proxy-list2.txt); do export http_proxy="http://$sLine" echo "Testing $sLine" wget --spider --timeout=5 --tries=1 http://www.example.com done rm proxy-list2.txt
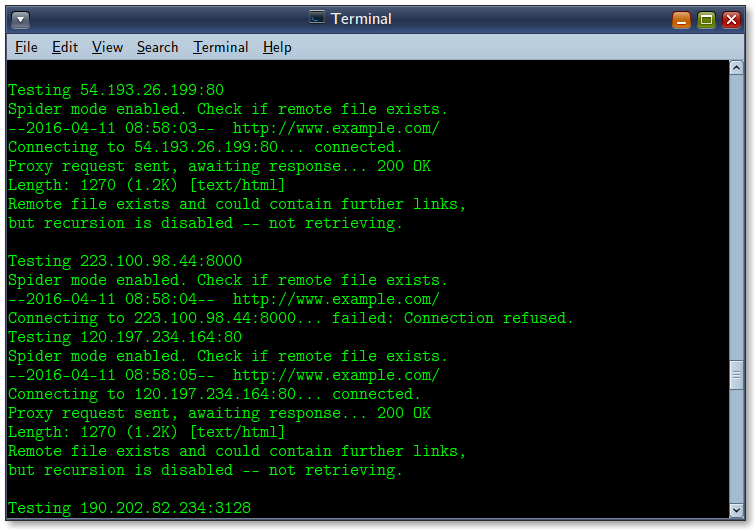
Output of the BASH script to check for working proxy IP addresses.
From the output of this script, you need to pick up those IPs that return “200 OK” status and put in a list of good working proxies. Then, create a new Firefox profile (firefox -ProfileManager) and changes its proxy to one from the working proxies list.
After that, whenever you need to access a site that is not available directly from your ISP, use the new Firefox profile that you created (firefox -P proxy-profile-name). Proxies tend to fail after some time but you can just use another from the list.
How to kill an application or process in Linux using BASH
The pkill command kills a named application but it does not work all the time. It can even when used with sudo. The good old kill command is the ultimate solution. Hence, I have use this alias in my .bashrc file in the home directory.
alias kll='bash ~/Scripts/kll.txt'
In the script file, I have this code:
for sID in `pgrep $1` do ps $sID kill -STOP $sID done for sID in `pgrep $1` do ps $sID kill -KILL $sID done
To kill an app, I type kll PROCESS-NAME. If it does not work, I would sudo it.
Quark – a command line audio player for Linux – Bash script to add a directory to player

I was writing a Nautilus Actions Configuration script for adding a directory to the playlist of Audacious (the Winamp clone for Linux).
Strangely, I forgot the name of the app. I did a search for command-line players but could not find it. Even cvlc was not listed. It was listed in the Ubuntu Software Manager. It is called Quark.
Quark calls itself as the anti-GUI player. It sits in the tray and you interact with it using a context menu from the tray – similar to Subhash VCDPlayer.
The GUI command for it is strange-quark. The CLI command is charm-quark.
Here is the script. You need to start the player with strange-quark.
charm-quark clear
for sFilename in $1/*
do
sExtension="${sFilename##*.}"
if [ $sExtension = "ogg" -o \
$sExtension = "OGG" -o \
$sExtension = "mp3" -o \
$sExtension = "MP3" -o \
$sExtension = "wav" -o \
$sExtension = "WAV" -o \
$sExtension = "wma" -o \
$sExtension = "WMA" ]
then
charm-quark append "$sFilename"
echo "$sFilename"
fi
done
charm-quark play
Here is another script to load a directory in Audacious2. There is some difficulty when reading pathnames with spaces. There are a few roundabout ways to do this. My solution is to just cd into the directory.
cd "$1"
for sFileName in *
do
sExtension="${sFileName##*.}"
if [ $sExtension = "ogg" -o \
$sExtension = "OGG" -o \
$sExtension = "mp3" -o \
$sExtension = "MP3" -o \
$sExtension = "wav" -o \
$sExtension = "WAV" -o \
$sExtension = "wma" -o \
$sExtension = "WMA" ]
then
sPlayList="$sPlaylist $1/$sFileName"
fi
done
audacious2 -E "$sPlaylist" &
audacious2 -p &
How to 2-pass custom-encode video files for portable MP4 video players using FFMPEG on Linux
I regularly download videos from YouTube using “Download Youtube video as MP4/FLV” Firefox plugin (https://addons.mozilla.org/en-US/firefox/addon/download-youtube/), as I don’t have time to sit through them. I can watch these videos later when I am traveling. However, my portable media player is the type that cannot play just about any format or any screen size. It requires video files to be of QVGA (320×240) resolution and MP4/WMV format. Video bit rates cannot be more than 1000 kbps. Max audio bit rates are I guess 384 kbps. Max frame rate is 30 per second.
On my computer, I have a full-blown FFMPEG installation that can decode and encode anything to anything. (https://trac.ffmpeg.org/wiki/CompilationGuide) I even have an extra FFMPEG installation that can convert videos to AMV format for those cheap Chinese players. (https://vsubhash.wordpress.com/2014/03/02/how-to-convert-any-video-file-to-amv-using-ffmpeg/)
For converting to the portable video player, here were my requirements:
- do 2-pass conversion
- prompt for video/audio bit rate so that it can match the download file or meet the max supported resolution of the device
- prompt for video size
- prompt for video frame rate
- copy the output file to desktop
- wait after conversion attempt so that any errors can be studied
ffmpeg -i "$1"
read -p "Enter video bitrate " iBitRate
read -p "Enter video framerate " iFrameRate
read -p "Enter video size " iVideoSize
read -p "Enter audio bitrate " iAudioBitrate
sOutputFileName=$(basename "$1")
sOutputFileName=~/Desktop/${sOutputFileName%.*}.mp4
sLogFileName=ffmpeg-`date +%G-%m-%g-%k-%M-%S`
echo $sLogFileName
echo "First pass"
ffmpeg -i "$1" -y -s $iVideoSize -f mp4 -pass 1 -passlogfile "$sLogFileName" -c:v mpeg4 -b:v `echo $iBitRate`k -r:v $iFrameRate -an /dev/null
echo "Second pass...."
ffmpeg -i "$1" -y -s $iVideoSize -f mp4 -pass 2 -passlogfile "$sLogFileName" -c:v mpeg4 -b:v `echo $iBitRate`K -r:v $iFrameRate -b:a `echo $iAudioBitrate`K "$sOutputFileName"
rm ~/ffmpeg*.log
read -p "Press Enter to quit" oNothing
The above script resides in a file. I call it via a Nautilus Actions Configuration command. This allows me to right click a downloaded video file and convert it from the context menu. The command opens a Terminal window where I can study the input file’s codecs, frame rate, bit rates, and size.
gnome-terminal -x sh -c "bash ~/c4w.txt ""$1"""
IMPORTANT: Youtube videos have all kinds of characters in their names. Many of these characters are illegal under FAT32 file system used by the video players. Rename the files to avoid problems.
How to decrypt PDF with just the user password from Linux bash
Encrypted PDF documents can have two passwords – owner and user. Shortly after I wrote the article “How To Remove Passwords From PDF Documents Using Linux Bash Command Line” (https://vsubhash.wordpress.com/2013/08/06/how-to-remove-passwords-from-pdf-documents-using-linux-bash/), ICICI Bank changed its system so that they now sent PDF documents encrypted with an owner password. pdftk was not going to work. qpdf to the rescue.
- Install qpdf.
sudo apt-get install qpdf
- Create a text file at some location in your computer (with extension txt as a precautionary measure). Replace my username (comacho) with yours.
read -p "Enter pathname of PDF for encryption: " sInputFileName sOutputFileName=$(basename "$sInputFileName") sOutputFileName=/home/comacho/Desktop/${sOutputFileName%.*}-unencrypted.pdf stty -echo read -p "Enter password to decrypt PDF: " sPassword stty echo qpdf --password=$sPassword --decrypt "$sInputFileName" "$sOutputFileName"
To decrypt PDF, just use the following command in Terminal:
sh path-to-the-txt-file
It will ask you for the pathname of the file. Copy the pathname of the file and paste it into the terminal. Next, it will ask you for the password (it will not be echoed to the screen). Then, your document will be decrypted and saved to your desktop.
How to download and listen to a podcast from bash terminal in Linux
Create a text file named podcast.txt in it, copy and paste this code in it, and save the file.
audacious2 "$1" &
cd ~/Downloads
wget --continue --no-check-certificate --retry-connrefused --waitretry=1 --read-timeout=20 --timeout=15 --tries 100 "$1"
audacious2 ${1##*/}
Now, open Terminal and paste the command bash podcast.txt URL-OF-THE-MP3. Replace URL-OF-THE-MP3 with the URL of the podcast. You don’t have to type out the entire line every time you want to download a podcast.
This bash script starts playing the podcast immediately. In the background, it also starts downloading the podcast. When the download is complete, it plays the downloaded podcast. Of course, the playback starts from the beginning again but you now have the ability to easily rewind or forward.
Some websites have switched to https but they have not installed an SSL certificate. For that reason, I have added the “–no-check-certificate” parameter to the wget command. Otherwise, wget might refuse to download the file. If you don’t like Audacious, then you could replace audacious2 with the name of your favourite music player. VLC has a command line interface called cvlc. I also recommend Exaile, which has a lot of plugins. Quark is an entirely command-line music player. I prefer Audacious2 as it has support for Winamp2 skins and presets.
Convert any video to AMV format using ffmpeg – For use with Chinese MP4 players
Yes, really AMV format – the bane of many Chinese portable media players… Using Nautilus Actions Configuration, FFMEG, FFMPEG AMV Codec Tools
Sometime last year, I needed a tough portable media player that I could use with my electronic projects. I bought the Zebronics Zebmate Cinema 1.8 player thinking that I was getting 8 GB space and video playing ability for Rs. 1600. The touchscreen is resistive, not capacitative, but that exactly fits my needs. Ordinary users will not like the player and should steer clear of this device. The menu interface is difficult.
It will play videos in only one format – AMV. No video converter that I have in Linux and Windows supports this format. On my Linux system, I have a custom-compiled ffmpeg installation that I thought covered everything. Surprisingly, it did not support AMV. There was a Google Code project titled “amv-codec-tools” that seemed to tailor-made for my requirement. I installed that but the video that it generated was full of artifacts. I had given up.
Today, I tried several Windoze software but all the video files they generated gave a “Format Error” message. I then decided to give ffmpeg-amv another attempt. Apparently, the guys who coded this tool seem to be all-Windows folk. The video does not accept OGV or other new formats. When I tried converting a WMV file with ffmpeg-amv, it produced a AMV video file that played both on Linux and the player without any issues. Totem Media Player does not play AMV but not so with VLC. VLC plays everything.
Here is how you convert any video file to AMV in Linux:
- Compile and install FFMPEG as per the guide at https://trac.ffmpeg.org/wiki/UbuntuCompilationGuide
- Install amv-codec-tools from https://github.com/vsubhash/amv-ffmpeg
- Use your regular FFMPEG executable to convert your existing videos (be they FLVs or MP4s) to WMV.
ffmpeg -i "to-be-converted.mp4" -vcodec msmpeg4 -qscale 1 -r:v 16 -s 160x120 -acodec wmav2 wmv-converted.wmv
- Use ffmpeg-amv to convert the resultant WMV file to AMV format
ffmpeg-amv -i "wmv-converted.wmv" -f amv -r 16 -ac 1 -ar 22050 -qmin 3 -qmax 3 converted.amv

UPDATE: I then wrote a Nautilus Actions Configuration. That way, I can just right-click any video file and then convert it to AMV. I use two BASH scripts so that I can monitor the conversion process in a Terminal window. The first bash script opens the terminal window and executes the second bash script inside it. The script converts the file first to WMV and then converts the WMV file to AMV format. After this conversion, the script deletes the WMV file leaving only the AMV file on the desktop.
amv-convert-na.txt
gnome-terminal -x sh -c "bash $HOME/Scripts/amv-convert.txt ""$1"""
amv-convert.txt
sWMVFile=${2%.*}.wmv
sAMVFile=${sWMVFile%.*}.amv
echo -e "\n\nWAIT: Converting $2 to WMV\n\n"
ffmpeg -i "$1/$2" -qscale 2 -vcodec msmpeg4 -r:v 16 -s 160x120 -acodec wmav2 "$1/$sWMVFile"
if [ $? -eq 0 ]; then
echo -e "\n\nWAIT: Converting $sWMVFile to AMV\n\n"
amv-ffmpeg -i "$1/$sWMVFile" -f amv -r 16 -ac 1 -ar 22050 -qmin 3 -qmax 3 "$1/$sAMVFile"
if [ $? -eq 0 ]; then
espeak "AMV conversion succeeded. Created $sAMVFile"
echo "\n\nSUCCESS: Converted to $1/$sAMVFile"
notify-send "AMV conversion" "Converted to $1/$sAMVFile"
rm "$sWMVFile"
else
espeak "AMV conversion failed."
echo "\n\nFAILURE: Unable to convert $1/$sWMVFile to AMV"
notify-send "AMV conversion" "Failed to $1/$sWMVFile to AMV"
fi
else
espeak "AMV conversion failed."
echo "\n\nFAILURE: Could not convert $2 to WMV"
notify-send "AMV conversion" "Failed to convert $1/$2 to WMV"
fi
Use this filter for Caja Actions or Nautilus Actions Configuration: *.3gp;*.asf;*.avi;*.dat;*.flv;*.ogv;*.ogm;*.mov;*.mp4;*.mpg;*.mpeg;*.mp4;*.swf;*.webm;*.wmv

Update (26-10-2018): The amv-ffmpeg converts to an intermediate format if the source video resolution and frame rate is different from that of the AMV container. So, the bash script has been updated to downsize the video in the WMV-creation step. Now, amv-ffmpeg converts directly to AMV. Earlier, the steps were as follows:
ffmpeg -i "to-be-converted.mp4" -qscale 1 -vcodec msmpeg4 -acodec wmav2 wmv-converted.wmv ffmpeg-amv -i "wmv-converted.wmv" -f amv -s 160x120 -r 16 -ac 1 -ar 22050 -qmin 3 -qmax 3 converted.amv
